Detection infrastructure health
Detection Infrastructure Health
Validated last quarter. Parser changed Tuesday. Agent coverage dropped on a critical subnet. The rule still exists. The heatmap is still green. Nothing fires until purple team proves it.
Detection infrastructure health is the condition of the telemetry and platform layers that determine whether detection capability is possible in production — not whether a rule is elegantly written in a library.
This is where “validated” silently becomes “broken” without anyone updating the record. If use case governance and effectiveness measurement are already in place, infrastructure health explains the hidden layer beneath both: lifecycle drift and effectiveness decay often start here.
Four ways detection programmes lose truth
Mature governance needs distinct language for distinct failure modes. They overlap in practice but require different diagnostics and owners:
| Failure mode | What diverges | Primary owner page |
|---|---|---|
| Lifecycle drift | Governed state vs reality — ownership, validation age, stale mappings | Lifecycle management |
| Effectiveness decay | Production performance vs declared confidence — alert quality, outcomes | Effectiveness |
| Infrastructure degradation | Environment vs assumptions — parsers, agents, pipelines, platform incidents | This page |
| Ownership fragmentation | Accountability across CTI, engineering, SOC handoffs | Use case management |
Infrastructure degradation is the hidden variable: it explains why validated logic stops working while lifecycle records and effectiveness dashboards lag behind production reality.

Three governed conditions: intent, environment, proof
Detection capability is not one metric. Leadership should separate three questions — and measure each with different evidence:
| Condition | Core question | If you only optimise this |
|---|---|---|
| Coverage (what should work) | What is mapped, prioritised, and owned against priority threats? | Heatmaps look complete while production proof stays thin. |
| Infrastructure health (what can work) | Can signal-path and platform layers execute mapped logic reliably? | You tune rules to compensate for broken pipes nobody recorded. |
| Effectiveness (what does work) | Do detections produce useful outcomes under live conditions? | You measure SOC pain without closing the loop to scope and ownership. |
Without infrastructure health, coverage remains intent and effectiveness becomes misleading activity metrics.

Infrastructure degradation in practice
| What still looks fine | What changed | What breaks |
|---|---|---|
| Rule deployed; validation passed | Field renamed in log source | Parser silently drops events; detection never fires |
| Agent coverage reported at 95% | Critical subnet excluded after network change | Blind spot on priority asset class |
| SIEM available; dashboards green | Ingestion latency spike after platform upgrade | Detection window missed; alerts arrive too late |
| Integration marked healthy | API credential rotated; connector failed quietly | Cross-platform correlation breaks |
| Validation succeeded in BAS | Production telemetry path differs from test environment | Lab proof does not transfer to live conditions |
Validation failures get misread as rule problems because engineering owns the rule text first. Pipelines, agents, parsers, and platform incidents require different diagnostics — and often different teams. When the wrong failure mode is diagnosed, tuning queues grow and trust in the SOC erodes.
Two dimensions of infrastructure health
Infrastructure health spans two independent but interdependent dimensions. Both must be measured and interpreted together:
- Technical signal health — can detection receive the data it depends on? Agent deployment, telemetry coverage, parsing, field extraction, completeness, ordering, and latency.
- Platform and service health — can detection execute reliably over time? Availability, incidents, change activity, capacity, and SLA adherence across SIEM, EDR, and supporting platforms.
They fail differently and require different ownership. A SIEM can be available while a pipeline starves it. Telemetry can be perfect while a scheduled change breaks execution. Treating both as one problem leads to misdiagnosis and endless rule rewrites.
Signal health often shows up as a working checklist: sensor coverage, agent version skew, logging integrity, parser stability, retention policies, and integration reliability. Platform health adds service incidents, capacity, and change windows that never appear in a rule repository.
The architecture page shows where these layers sit in the stack; this page defines the health dimension those diagrams assume.
Infrastructure health in SecuMap
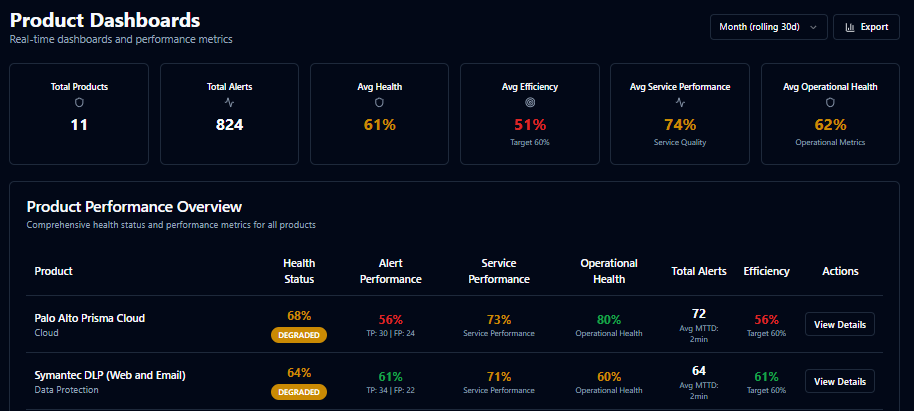
From infrastructure diagnosis to a governed record
Infrastructure health is not a separate dashboard concern. It is one of three governed conditions that must stay linked to the same use cases, owners, and validation evidence.
A Detection System of Record (DSoR) operationalises this continuously: linking coverage intent, infrastructure inputs, validation evidence, and production outcomes so teams do not tune rules to mask broken pipes without recording the trade-off.
SecuMap implements the DSoR category above SIEM, EDR, BAS, and CTI — without replacing them. The canonical definition lives on the Detection System of Record hub. For narrative depth on misread failures, read The hidden variable on the blog.
Frequently asked questions
What is detection infrastructure health?
The condition of telemetry and platform layers that determine whether detections can work in production — signal-path health and platform service health — independent of rule quality on paper.
Why do validated detections stop working?
Often because the environment changed: parser drift, agent gaps, integration failures, or platform incidents — not because the rule text was wrong.
Is infrastructure health the same as coverage?
No. Coverage describes what is mapped and intended. Infrastructure health describes whether the environment can deliver what coverage assumes.
How is infrastructure degradation different from lifecycle drift?
Lifecycle drift is governed state diverging from reality. Infrastructure degradation is the data path or platform layer failing while the use case record still looks current.
How does infrastructure health relate to a Detection System of Record?
It is one governed condition alongside coverage and effectiveness. A DSoR links all three in one auditable model. See the Detection System of Record hub.