The Hidden Variable: Detection Infrastructure Health
Category definition (structural): Detection infrastructure health — this post is the narrative and failure-mode depth.
This also pairs with the category explainer what is a Detection System of Record? The point here is the substrate: whether telemetry and platforms support the model you think you are running.
Before you rewrite the rule, ask what the substrate is doing. When a detection fails validation, the instinctive response is to examine the rule logic. Tune the conditions. Rewrite the query. Add verbosity.
But what if the telemetry beneath the rule is the problem?
Agents fall out of date. Logging configurations drift. Fields are dropped in parsing pipelines. Data latency increases. Retention policies shift. Integration connections break silently. Sensor coverage becomes incomplete across the estate.
In those cases, the rule did not decay. The infrastructure did.
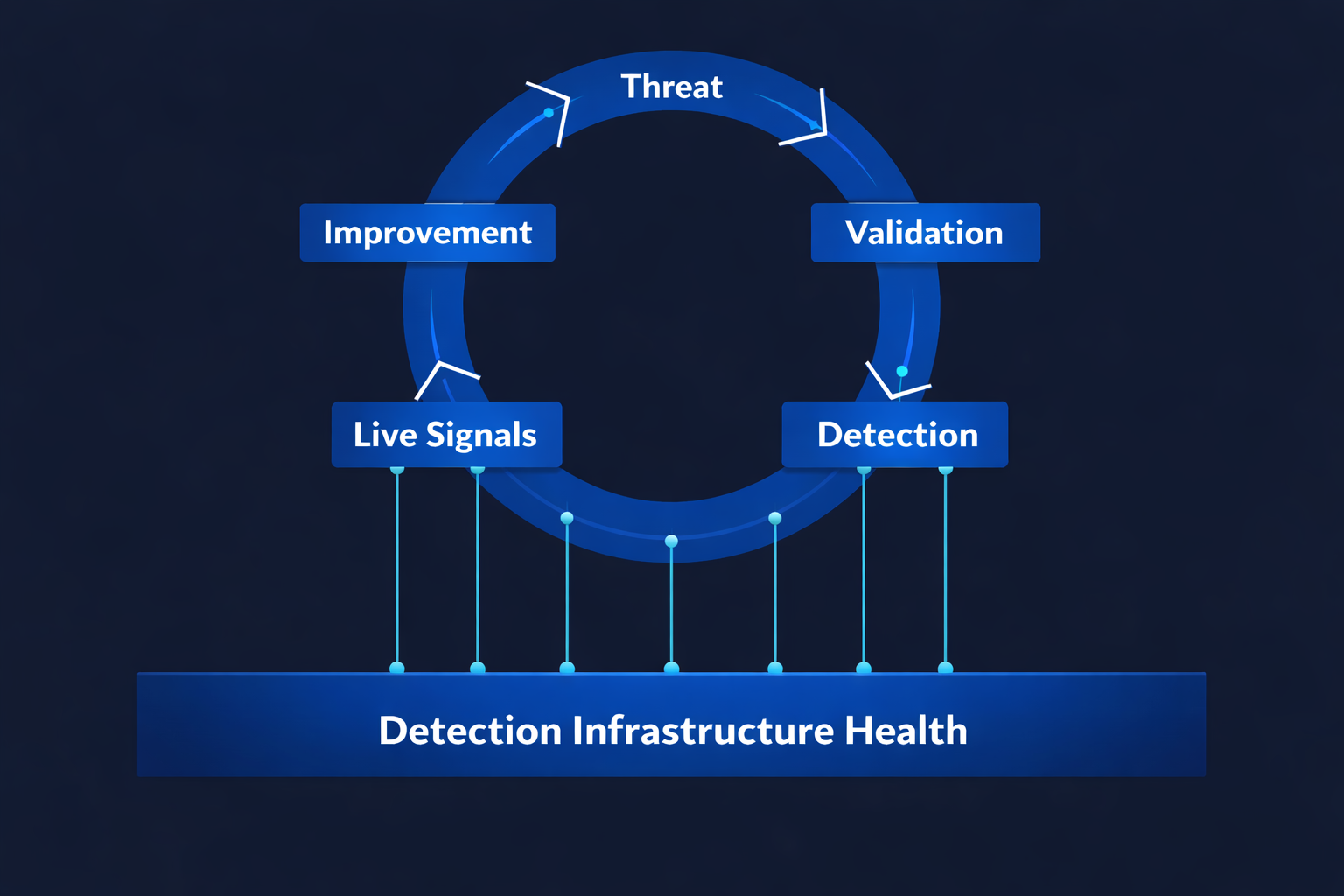
Detection Infrastructure Health and the operating model
This is one of the most common and least diagnosed blind spots in detection engineering: Detection Infrastructure Health — the foundational layer of any threat-to-detection operating model.
Detection Infrastructure Health governs the operational condition of the telemetry pipelines that make detection possible. It encompasses sensor deployment coverage, agent uptime and version drift, logging configuration integrity, parsing and field mapping stability, data completeness and latency, retention fidelity, and integration reliability across platforms.
When Detection Infrastructure Health degrades, detection effectiveness degrades — even when the rule logic is perfect.
The second layer: Detection Platform Operational Health
But there is a second layer that is rarely examined: Detection Platform Operational Health. Even when telemetry pipelines are healthy, detections can silently fail when the platforms responsible for processing that telemetry are not reliably maintained. In large enterprises these platforms are often operated by separate internal teams or external providers, meaning outages, configuration drift, change activity, and service incidents can directly impact detection capability.
Questions that should be routinely asked rarely are:
- Is the detection platform meeting its availability SLA?
- How often are service incidents affecting detection capability?
- How frequently are platform changes occurring — and what impact do they have on detection logic?
- Is the platform operating within expected performance and capacity thresholds?
When platform reliability degrades, detections degrade — even when both telemetry and rule logic are correct.
Misdiagnosing the failure mode
This means many organisations are misdiagnosing weak detections as logic failures when they are in fact infrastructure or platform failures.
They tune rules to compensate for broken pipelines. They add conditions to compensate for incomplete telemetry. They rewrite logic to compensate for unreliable platforms. They are treating the symptom. The cause goes unexamined.
A Detection System of Record (DSoR) is the category built to make this visible: a governed layer that holds threat context, coverage, validation, and operational health in one place so you can tell whether a failure is “the rule” or “the world the rule runs in.” The category hub is detection-system.html; the structural definition of infrastructure health is detection-infrastructure-health.html; the architecture view is architecture.html. For adjacent comparisons, see SIEM vs Detection System of Record (evidence and governance vs execution) and BAS vs continuous validation (point-in-time simulation vs production proof).